Python的幕后#2: CPython 编译器是如何工作的
本文已获原文作者Victor Skvortsov授权
在本系列的 第一篇 中我们介绍了CPython VM。我们已经了解到它可以通过执行一系列称为字节码的指令来工作。 我们还看到,Python字节码不足以完整描述一段代码的功能。 这就是为什么存在代码对象的原因。执行代码块比如模块或者函数意味着执行相应的代码对象。代码对象包含了代码块的字节码, 该代码块中使用的常量和变量以及代码块的各种属性。
通常,Python程序员不编写字节码,也不创建代码对象,而是编写普通的Python代码。 因此,CPython必须能够从源代码创建代码对象。 这项工作由CPython编译器完成。 在这一部分中,我们将探讨其工作原理。
Note: 在本文中,我指的是CPython 3.9。 随着CPython的发展,某些实现细节肯定会发生变化。 我将尝试跟踪重要的更改并添加更新说明。
什么是CPython 编译器?
我们了解了CPython编译器的职责,但是在研究其实现方式之前,让我们弄清楚为什么首先将其称为编译器。
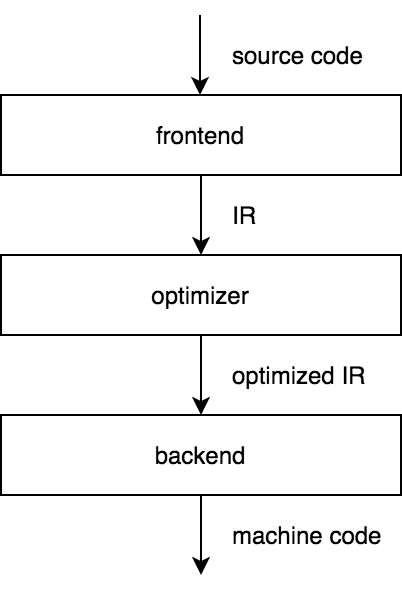
一般而言,编译器是将一种语言的程序等价翻译成另一种语言的程序的程序。 编译器的类型很多,但是在大多数情况下,编译器是指静态编译器,它可以将高级语言的程序转换为机器代码。 CPython编译器与这种类型的编译器有共同点吗? 为了回答这个问题,让我们看一下传统静态编译器的三阶段设计。
{kind=link}
编译器的前端将源代码转换为某种中间表示(IR)。 然后,优化器获取一个IR,对其进行优化,然后将优化的IR传递给生成机器代码的后端。 如果我们选择不是特定于任何源语言和任何目标机器的IR,那么我们将获得三阶段设计的主要好处:对于支持新语言的编译器,仅需要一个附加的前端,并且支持一个新的目标平台,只需要一个新的后端。
LLVM工具链是该模型成功的一个很好的例子。 有一些C,Rust,Swift和许多其他编程语言的前端,它们依赖LLVM提供编译器的更复杂部分。 LLVM的创建者Chris Lattner很好地概述了其体系结构。
但是,CPython不需要支持多种语言和目标平台,而只需支持Python代码和CPython VM。 尽管如此,CPython编译器的实现是三阶段的。 要了解原因,我们应该更详细地研究三阶段编译器的结构。
{kind=link}
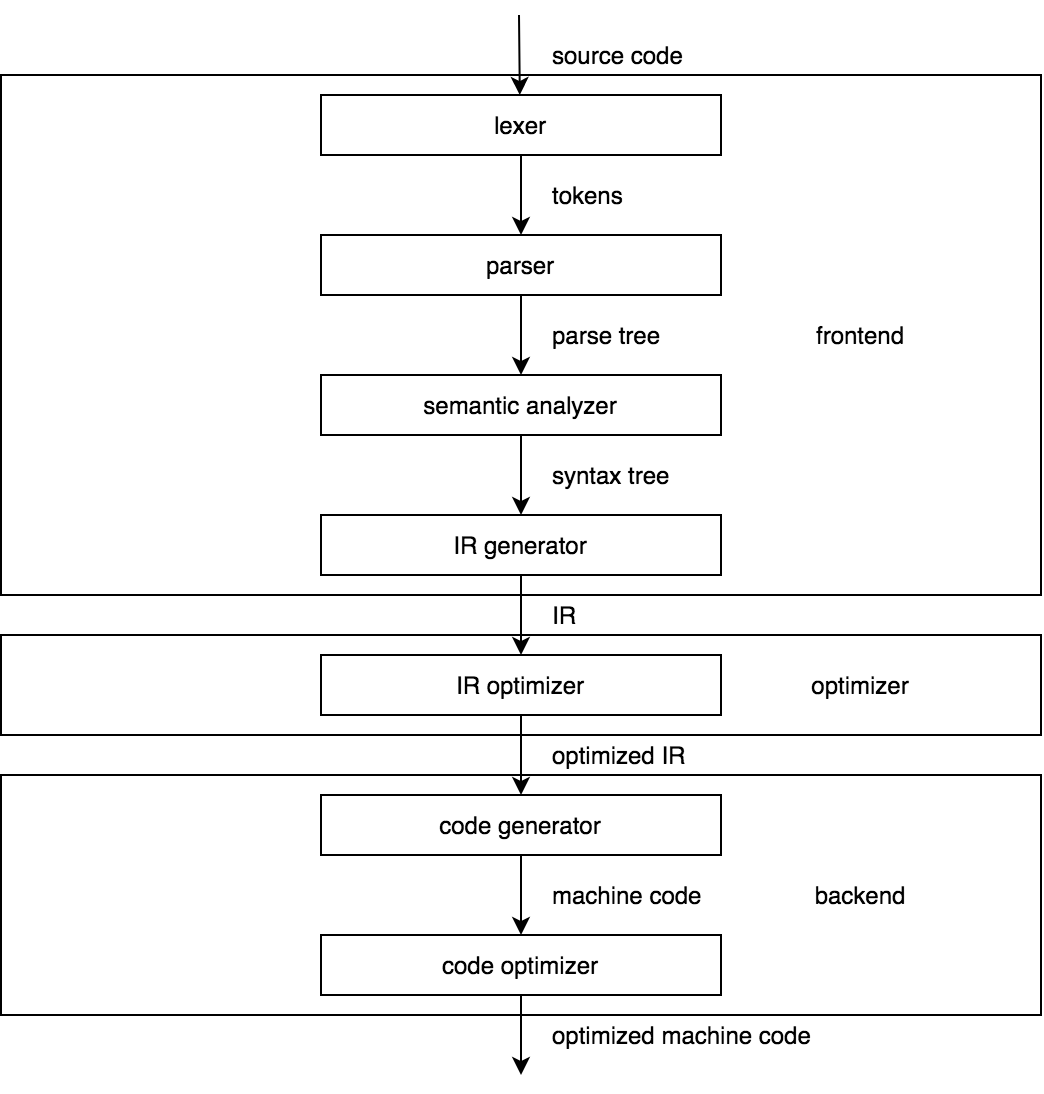
上图是经典编译器的模型。 现在将其与下图中的CPython编译器的体系结构进行比较。
{kind=link}
看起来很相似,不是吗? 这里的重点是,以前学习过编译器的任何人都应该熟悉CPython编译器的结构。如果没有的话,一本著名的龙书是对编译器构造理论的出色介绍。 它很长,但是即使只阅读前几章,您也会从中受益。
我们进行的比较需要提前解释一些东西。 首先,从3.9版本开始,CPython默认使用一个新的解析器,该解析器立即输出AST(抽象语法树),而无需进行构建解析树的中间步骤。 因此,CPython编译器的模型被进一步简化。 其次,与静态编译器的相应阶段相比,CPython编译器的某些现成阶段做得很少,有人可能会说CPython编译器不过是前端。 我们不会采用hardcore compiler 编写者的这种观点。
编译器架构概述
这些图很不错,但是它们隐藏了许多细节并且可能会引起误解,因此让我们花一些时间来讨论CPython编译器的总体设计。
CPython编译器的两个主要组件是:
- 前端
- 后端
前端获取Python代码并生成AST。后端获取AST并生成一个代码对象。在整个CPython源代码中,术语“解析器”和“编译器”分别用于前端和后端。这是编译器一词的另一含义。最好将其称为类似代码对象生成器的名称,但是我们会坚持使用编译器,因为它似乎不会造成太多麻烦。
解析器的工作是检查输入是否在语法上正确的Python代码。 如果不是,则解析器报告如下错误:
x = y = = 12
^
SyntaxError: invalid syntax
如果输入正确,将那么解析器将根据语法规则对其进行组织。语法定义语言的语法。 形式语法的概念对于我们的讨论是如此重要,我想我们应该花点时间回顾一下它的正式定义。
根据经典定义,语法是一个包含四个项目的元组:
- Σ – 一组有限的终结符,或简单的终结符(通常用小写字母表示)
- N – 一组有限的非终结符号,或简称为非终结符(通常用大写字母表示)。
- P – 生成式, 一套生产规则。 对于上下文无关的语法(包括Python语法),生产规则只是从非终结符到任意序列的终结符和非终结符的映射,例如 A→aB。
- S – 识别符.
文法定义了一种语言,其中包含可以通过应用生成式生成的所有终结符序列。为了生成某个序列,以符号S开头,然后根据生成式将每个非终结符号递归替换为一个序列,直到整个序列由终结符组成。 使用已建立的约定惯例,列出生成式以指定语法就足够了。 例如,这是一个简单的语法,该语法生成交替的一和零的序列:
S→10S|10
当我们更详细地分析解析器时,我们将继续讨论文法。
Abstract Syntax Tree
解析器的最终目标是生成AST。AST是一种树形数据结构,用作源代码的高级表示。这是标准ast模块产生的相应AST的一段代码和转储的示例
x = 123
f(x)
$ python -m ast example1.py
Module(
body=[
Assign(
targets=[
Name(id='x', ctx=Store())],
value=Constant(value=123)),
Expr(
value=Call(
func=Name(id='f', ctx=Load()),
args=[
Name(id='x', ctx=Load())],
keywords=[]))],
type_ignores=[])
AST节点的类型使用Zephyr抽象文法定义语言 (ASDL) 。ASDL是一种简单的声明性语言,用于描述树状IR,即AST。这是Parser/Python.asdl中的Assign和Expr节点的定义:
stmt = ... | Assign(expr* targets, expr value, string? type_comment) | ...
expr = ... | Call(expr func, expr* args, keyword* keywords) | ...
ASDL规范让我们了解了Python AST的样子。但是,解析器需要在C代码中表示AST。幸运的是,从AST节点的ASDL描述中生成C结构很容易。这就是CPython所做的,结果如下所示:
struct _stmt {
enum _stmt_kind kind;
union {
// ... other kinds of statements
struct {
asdl_seq *targets;
expr_ty value;
string type_comment;
} Assign;
// ... other kinds of statements
} v;
int lineno;
int col_offset;
int end_lineno;
int end_col_offset;
};
struct _expr {
enum _expr_kind kind;
union {
// ... other kinds of expressions
struct {
expr_ty func;
asdl_seq *args;
asdl_seq *keywords;
} Call;
// ... other kinds of expressions
} v;
// ... same as in _stmt
};
AST是一种易于使用的表示形式。 它告诉程序做什么,隐藏所有不必要的信息,例如缩进,标点和其他Python的句法特性。
AST表示法的主要受益者之一是编译器, which can walk an AST and emit bytecode in a relatively straightforward manner. 除了编译器之外,许多Python工具都使用AST来处理Python代码。例如,pytest在assert语句失败时,对AST进行更改以提供有用的信息,它本身不执行任何操作,但是如果表达式的计算结果为False,则会引发AssertionError。 另一个例子是Bandit,它通过分析AST在Python代码中发现常见的安全问题。
现在,当我们稍微学习了Python AST之后,我们可以看看解析器是如何从源代码中构建它的。
从源代码到AST
事实上,正如我前面所说,从3.9版本开始,CPython的解析器不是一个,而是两个。新的解析器是默认使用的,也可以通过传递-X oldparser选项来使用旧的解析器。 但在CPython 3.10中,旧的解析器将被完全删除。这两个解析器有很大的不同。我们将重点讨论新的解析器,但在此之前,先讨论一下旧的解析器。
旧的文法分析器
在很长一段时间里,Python的语法是由生成式文法正式定义的。问题在于,生成式文法并不能直接对应于能够解析这些序列的解析算法。幸运的是,聪明的人已经能够区分出生成文法的类别,并为其建立相应的解析器。这些文法包括上下文无关、LL(k)、LR(k)、LALR 和许多其他类型的文法。Python文法是LL(1)。它使用一种扩展的 Backus-Naur 形式 (EBNF) 来指定。为了了解如何使用它来描述Python的语法,请看一下while语句的规则。
file_input: (NEWLINE | stmt)* ENDMARKER
stmt: simple_stmt | compound_stmt
compound_stmt: ... | while_stmt | ...
while_stmt: 'while' namedexpr_test ':' suite ['else' ':' suite]
suite: simple_stmt | NEWLINE INDENT stmt+ DEDENT
...
CPython扩展了传统记法,具有以下特点:
- 替代分组: (a | b)
- 选择部分: [a]
- 零个或多个和一个或多个重复: a* 和 a+
我们可以看到为什么Guido van Rossum选择使用正则表达式。它们允许以一种更自然(对程序员来说)的方式来表达编程语言的语法。不写A→aA|a ,我们可以直接写A→a+。这个选择是有代价的。CPython必须开发一种方法来支持扩展符号。
LL(1)文法的解析是一个已解决的问题。解决的方法是作为自上而下的解析器的下推自动机(PDA)。PDA通过使用栈模拟输入字符串的生成进行操作。为了解析一些输入,它从栈上的起始符号开始。然后,它查看输入中的第一个符号,猜测应该对起始符号应用哪条规则,并将其替换为该规则的右侧。如果栈上的栈顶符号是一个终结符,与输入中的下一个符号相匹配,PDA就会把它出栈并跳过匹配的符号。如果栈顶符号是一个非终结符,PDA会根据输入中的下一个符号,尝试猜测要替换它的规则。这个过程一直重复,直到扫描完整个输入,或者如果PDA无法将栈上的一个终结符与输入中的下一个符号相匹配。后一种情况意味着输入字符串无法被解析。
CPython由于生成式的写法,不能直接使用这种方法,所以必须开发新的方法。
为了支持扩展的符号,旧的解析器用确定性有限自动机(DFA)来表示语法的每条规则,DFA以等价于正则表达式而闻名。解析器本身是一个像PDA一样的基于栈的自动机,但它不是在栈上推送符号,而是推送DFA的状态。下面是老解析器使用的关键数据结构。
typedef struct {
int s_state; /* State in current DFA */
const dfa *s_dfa; /* Current DFA */
struct _node *s_parent; /* Where to add next node */
} stackentry;
typedef struct {
stackentry *s_top; /* Top entry */
stackentry s_base[MAXSTACK];/* Array of stack entries */
/* NB The stack grows down */
} stack;
typedef struct {
stack p_stack; /* Stack of parser states */
grammar *p_grammar; /* Grammar to use */
// basically, a collection of DFAs
node *p_tree; /* Top of parse tree */
// ...
} parser_state;
还有Parser/parser.c中的注释,总结了这个方法:
一个解析规则用一个确定性有限状态自动机(DFA)来表示。DFA中的一个节点代表解析器的一个状态;一个弧线代表一个过渡。状态迁移要么用终结符标注,要么用非终结符标注。当解析器决定跟随一个标有非终结符的弧线时,它就会被递归调用,以代表该解析规则的DFA作为初始状态;当该DFA接受时,调用它的解析器就会继续。递归调用的解析器构建的解析树作为子树插入到当前的解析树中。
解析器在解析输入时,会建立一棵解析树,也称为具体语法树(CST)。与AST相反,解析树直接对应于推导输入时应用的规则。解析树中的所有节点都使用同一个节点结构来表示。
typedef struct _node {
short n_type;
char *n_str;
int n_lineno;
int n_col_offset;
int n_nchildren;
struct _node *n_child;
int n_end_lineno;
int n_end_col_offset;
} node;
然而,一个解析树并不是编译器所期待的。它必须被转换为AST。这项工作是在Python/ast.c中完成的,算法是递归地遍历一棵解析树,并将其节点转换成AST节点。几乎没有人觉得这近6000行代码很惊艳。
词法分析器
从语法的角度来看,Python不是一门简单的语言。不过,Python 文法看起来很简单,包括注释在内,大约可以只有 200 行。这是因为文法的符号是标记而不是单个字符。一个符号由类型来表示,如NUMBER、NAME、NEWLINE、值和在源代码中的位置。CPython区分了63种符号类型,这些类型都列在文法/符号中。我们可以使用标准的tokenize模块来查看一个词法分析后的程序的样子。
def x_plus(x):
if x >= 0:
return x
return 0
$ python -m tokenize example2.py
0,0-0,0: ENCODING 'utf-8'
1,0-1,3: NAME 'def'
1,4-1,10: NAME 'x_plus'
1,10-1,11: OP '('
1,11-1,12: NAME 'x'
1,12-1,13: OP ')'
1,13-1,14: OP ':'
1,14-1,15: NEWLINE '\n'
2,0-2,4: INDENT ' '
2,4-2,6: NAME 'if'
2,7-2,8: NAME 'x'
2,9-2,11: OP '>='
2,12-2,13: NUMBER '0'
2,13-2,14: OP ':'
2,14-2,15: NEWLINE '\n'
3,0-3,8: INDENT ' '
3,8-3,14: NAME 'return'
3,15-3,16: NAME 'x'
3,16-3,17: NEWLINE '\n'
4,4-4,4: DEDENT ''
4,4-4,10: NAME 'return'
4,11-4,12: NUMBER '0'
4,12-4,13: NEWLINE '\n'
5,0-5,0: DEDENT ''
5,0-5,0: ENDMARKER ''
这是该程序在文法解析器中的样子。当文法解析器需要一个符号时,它就会向词法分析器请求一个符号。词法分析器每次从缓冲区中读取一个字符,并尝试将看到的前缀与某种类型的符号进行匹配。词法分析器如何处理不同的编码?它依赖于io模块。首先,词法分析器检测编码。如果没有指定编码,它默认为UTF-8。然后,词法分析器用 C 调用打开一个文件,相当于 Python 的 open(fd, mode='r', encoding=enc),并通过调用readline()函数读取文件内容。这个函数返回一个unicode字符串。词法分析器读取的字符只是该字符串UTF-8表示的字节(或EOF)。
我们可以直接在文法中定义一个数字或一个名称是什么,尽管这会变得更加复杂。我们不能做的是在文法中表达缩进的意义,而不使其成为上下文敏感的,因此,缩进不适合解析。词法分析器通过提供 INDENT 和 DEDENT 符号,使解析器的工作变得更加容易。它们的意思就是像 C 语言中大括号的意思。词法分析器有足够的能力来处理缩进,因为它有状态。当前的缩进级别被保存在栈的顶部。当级别增加时,它的缩进会被推送到栈上。如果级别降低,所有更高的级别都会从堆栈中弹出。
旧的文法分析器是CPython代码库中的一个不小的部分。文法的DFA是自动生成的,但文法分析器的其他部分是手工编写的。这与新的文法分析器形成鲜明对比,新的文法分析器似乎是解决Python代码解析问题的一个更优雅的方案。
新的文法分析器
新的解析器带有新的文法。该文法法为解析表达语法(PEG)。要明白的是,PEG不仅仅是一类文法。 这是另一种定义文法的方式。PEGs是由Bryan Ford在2004年提出的,作为描述一种编程语言并根据描述生成解析器的工具 。PEG与传统的形式化文法不同的是,它的规则将非终结符映射到解析表达式上,而不仅仅是符号序列。 这与CPython的理念是一致的。 解析表达式是归纳性定义的。 如果e、e1和e2是解析表达式, 那就意味着它是:
- 空字符串
- 任何终结符
- 任何非终结符
- e1e2, 一个序列
- e1/e2, 优先选择
- e∗, 零次或多次重复
- !e, 非谓词
PEGs是分析文法,这意味着它们不仅可以生成语言,还可以分析它们。Ford将解析表达式e识别输入x的含义形式化,基本上,任何用某个解析表达式识别输入的尝试,要么成功,要么失败, 消费掉输入x或者不消费。例如,将解析表达式a应用于输入ab的结果是成功,并消费掉a。
这种形式化允许将任何PEG转换为递归下降解析器 。递归下降解析器将文法的每个非终结符与解析函数相关联。 对于PEG来说,解析函数的功能是相应解析表达式的实现。 如果解析表达式包含非终结符,则将其递归调用其解析函数。
一个非终结符可能有多个产生规则。递归下降解析器必须决定哪一个是用来推导输入的。如果一个文法是LL(k),一个解析器可以查看输入中的下一个k个字符,并预测正确的规则。这样的解析器称为预测性解析器。如果无法预测,则采用回溯法。采用回溯法的解析器会尝试一条规则,如果失败,则回溯并尝试另一条规则。这正是PEG中优先选择操作符的作用。所以,PEG解析器是一个带回溯的递归下降解析器。
回溯方法功能强大,但计算成本很高。 考虑一个简单的例子。 我们将表达式AB/A 应用于在A上成功但在B上失败的输入。根据对优先选择运算符的解释,解析器首先尝试识别A,成功,然后尝试识别B。失败后再尝试识别A。由于这样的冗余计算,解析时间可能是输入大小的指数。为了解决这个问题, Ford suggested 使用记忆技术,即缓存函数调用的结果。使用此技术,可以保证解析器(称为packrat解析器)可以在线性时间内工作,但要消耗更多的内存。 这就是CPython的新解析器所做的。 这是一个packrat解析器!
无论新的解析器有多好,都必须给出替换旧解析器的理由。这就是PEPs的作用。 PEP 617 – New PEG parser for CPython 给出了新旧解析器的背景,并解释了过渡背后的原因。简而言之,新的解析器取消了对语法的LL(1)限制,应该更容易维护。Guido van Rossum 写了 一个系列关于PEG解析的优秀文章, 在这写文章里他详细介绍了如何实现一个简单的PEG解析器。接下来,我们将看看它的CPython实现。
您可能会惊讶地发现,新的文法文件比旧的大了三倍多。这是因为新的文法不仅仅是一个文法,而是一个语法导向翻译方案(SDTS)。SDTS是一个在规则上附加了动作的文法。一个动作是一段代码。当解析器将相应的规则应用于输入并成功时,它就会执行一个动作。CPython在解析时使用action来构建AST。要想知道是怎么做的,我们来看看新的语法是什么样子的。我们已经看到了旧语法的while语句的规则,所以这里是它们的新样子。
file[mod_ty]: a=[statements] ENDMARKER { _PyPegen_make_module(p, a) }
statements[asdl_seq*]: a=statement+ { _PyPegen_seq_flatten(p, a) }
statement[asdl_seq*]: a=compound_stmt { _PyPegen_singleton_seq(p, a) } | simple_stmt
compound_stmt[stmt_ty]:
| ...
| &'while' while_stmt
while_stmt[stmt_ty]:
| 'while' a=named_expression ':' b=block c=[else_block] { _Py_While(a, b, c, EXTRA) }
...
每个规则都以非终结符的名称开头。 解析函数返回结果的C类型。 右侧是解析表达式。 花括号中的代码表示一个动作。 动作是返回AST节点或其字段的简单函数调用。
新的解析器是Parser/pegen / parse.c。它由解析器生成器自动生成。解析器生成器是用Python编写的。这是一个用C或Python获取语法并生成PEG解析器的程序。文法在文法文件中描述,并由Grammar类的实例表示。要创建这样的实例,文法文件必须有一个解析器。 此解析器也是由解析器生成器自动从metagrammar。这就是解析器生成器可以在Python中生成解析器的原因。但是解析metagrammar的是什么呢?好吧,它与语法的符号相同,因此生成的文法解析器也能够解析metagrammar。当然,文法分析器必须是自举的,第一个版本必须是手工编写的。完成后,所有解析器都可以自动生成。
与旧的解析器一样,新的解析器从词法分析器获取符号。 对于PEG解析器而言,这是特殊的,因为它可以统一标记和解析。 直到我们看到了tokenizer所做的非凡的工作,因此CPython开发人员决定使用它。
到此为止,我们结束了对解析的讨论,接下来看下AST。
AST 优化
CPython编译器的架构图向我们展示了AST优化器与解析器和编译器并列。这可能过分强调了优化器的作用。AST优化器只是常量折叠, 其在CPython3.7中才被引入。在CPython3.7之前, 常量折叠是在后期由窥孔优化完成的。尽管如此,由于AST优化器的存在,我们可以写出这样的东西。
n = 2 ** 32 # easier to write and to read
并希望在编译时计算出来。
一个不太明显的优化的例子是将一个常数列表和一个常数集合分别转换为一个元组和一个frozenset。当在 in 或 not in 右侧使用一个list或者set时,就会进行这种优化。
从AST到代码对象
到目前为止,我们一直在研究CPython是如何从源代码中创建AST的,但正如我们在第一篇文章中看到的,CPython虚拟机对AST一无所知,只能执行一个代码对象。将AST转换为代码对象是编译器的工作。更具体地说,编译器必须返回模块的代码对象,其中包含模块的字节码以及模块中其他代码块的代码对象,如定义的函数和类。
有时候,理解解决问题的最好方法是自己的思考。让我们思考一下,如果我们是编译器,我们会怎么做?.我们从代表一个模块的AST的根节点开始。该节点的子节点为语句。让我们假设第一条语句是一个简单的赋值,如x = 1。它由AssignAST节点表示: Assign(targets=[Name(id='x', ctx=Store())], value=Constant(value=1)). 为了将这个节点转换为代码对象,我们需要创建一个代码对象,将常量1存储在代码对象的常量列表中,将变量x的名字存储在代码对象的名称列表中,并发出LOAD_CONST和STORE_NAME指令。 我们可以写一个函数来做这件事。但即使是一个简单的任务也可能很棘手。 例如,想象一下,在一个函数体内进行同样的赋值。I如果x是一个局部变量,我们应该发出STORE_FAST指令。 如果x是一个全局变量,我们应该发出STORE_GLOBAL指令。 最后,如果x被一个嵌套函数所引用,我们应该发出STORE_DEREF指令。问题是要确定变量x的类型是什么。CPython通过在编译前建立一个符号表来解决这个问题。
符号表
符号表中包含关于代码块和所使用的符号的信息。它由一个symtable结构体和一个symtable_entry结构体的集合表示,程序中的每个代码块都有一个。一个符号表项包含了一个代码块的属性,包括它的名字、它的类型(模块、类或函数)和一个字典,它将代码块中使用的变量名称映射到表示其范围和用途的标志上。以下是_symtable_entry 结构体的完整定义:
typedef struct _symtable_entry {
PyObject_HEAD
PyObject *ste_id; /* int: key in ste_table->st_blocks */
PyObject *ste_symbols; /* dict: variable names to flags */
PyObject *ste_name; /* string: name of current block */
PyObject *ste_varnames; /* list of function parameters */
PyObject *ste_children; /* list of child blocks */
PyObject *ste_directives;/* locations of global and nonlocal statements */
_Py_block_ty ste_type; /* module, class, or function */
int ste_nested; /* true if block is nested */
unsigned ste_free : 1; /* true if block has free variables */
unsigned ste_child_free : 1; /* true if a child block has free vars,
including free refs to globals */
unsigned ste_generator : 1; /* true if namespace is a generator */
unsigned ste_coroutine : 1; /* true if namespace is a coroutine */
unsigned ste_comprehension : 1; /* true if namespace is a list comprehension */
unsigned ste_varargs : 1; /* true if block has varargs */
unsigned ste_varkeywords : 1; /* true if block has varkeywords */
unsigned ste_returns_value : 1; /* true if namespace uses return with
an argument */
unsigned ste_needs_class_closure : 1; /* for class scopes, true if a
closure over __class__
should be created */
unsigned ste_comp_iter_target : 1; /* true if visiting comprehension target */
int ste_comp_iter_expr; /* non-zero if visiting a comprehension range expression */
int ste_lineno; /* first line of block */
int ste_col_offset; /* offset of first line of block */
int ste_opt_lineno; /* lineno of last exec or import * */
int ste_opt_col_offset; /* offset of last exec or import * */
struct symtable *ste_table;
} PySTEntryObject;
CPython使用术语命名空间作为符号表背景下代码块的同义词。因此,我们可以说,符号表项是对命名空间的描述。符号表项通过ste_children字段形成程序中所有命名空间的层次结构,该字段是一个子命名空间的列表。我们可以使用标准库中的symtable模块来探索这个层次结构
# example3.py
def func(x):
lc = [x+i for i in range(10)]
return lc
>>> from symtable import symtable
>>> f = open('example3.py')
>>> st = symtable(f.read(), 'example3.py', 'exec') # module's symtable entry
>>> dir(st)
[..., 'get_children', 'get_id', 'get_identifiers', 'get_lineno', 'get_name',
'get_symbols', 'get_type', 'has_children', 'is_nested', 'is_optimized', 'lookup']
>>> st.get_children()
[<Function SymbolTable for func in example3.py>]
>>> func_st = st.get_children()[0] # func's symtable entry
>>> func_st.get_children()
[<Function SymbolTable for listcomp in example3.py>]
>>> lc_st = func_st.get_children()[0] # list comprehension's symtable entry
>>> lc_st.get_symbols()
[<symbol '.0'>, <symbol 'i'>, <symbol 'x'>]
>>> x_sym = lc_st.get_symbols()[2]
>>> dir(x_sym)
[..., 'get_name', 'get_namespace', 'get_namespaces', 'is_annotated',
'is_assigned', 'is_declared_global', 'is_free', 'is_global', 'is_imported',
'is_local', 'is_namespace', 'is_nonlocal', 'is_parameter', 'is_referenced']
>>> x_sym.is_local(), x_sym.is_free()
(False, True)
这个例子表明,每个代码块都有一个相应的符号表项。我们在列表推导式的命名空间内意外地遇到了奇怪的.0符号。这个命名空间并不包含range符号,这也很奇怪。这是因为列表推导式被实现为一个匿名函数,range(10)被作为一个参数传递给它。这个参数的引用是".0"。CPython还隐藏了什么黑盒?
符号表项是分两次构建的。在第一遍中,CPython遍历AST,为它遇到的每个代码块创建一个符号表项。它也会收集一些可以当场收集的信息,比如一个符号是否在该块中被定义或使用。但有些信息在第一遍时很难推导出来。考虑一下这个例子:
def top():
def nested():
return x + 1
x = 10
...
在为nested()函数构建符号表项时,我们无法判断x是全局变量还是自由变量,即在top()函数中定义,因为我们还没有看到赋值。
Python通过做第二遍遍历来解决这个问题。在第二遍的开始,我们已经知道了符号的定义和使用。缺少的信息通过从顶部开始递归访问所有的符号表项来填补。在nested闭包函数的同层定义的符号被向下传递到nested的命名空间,而nested闭包函数内的作用域中自由变量的名字被传递回来。
符号表项是用symtable结构管理的。它既用来构建符号表项,也用来在编译过程中访问它们。让我们看一下它的定义:
struct symtable {
PyObject *st_filename; /* name of file being compiled,
decoded from the filesystem encoding */
struct _symtable_entry *st_cur; /* current symbol table entry */
struct _symtable_entry *st_top; /* symbol table entry for module */
PyObject *st_blocks; /* dict: map AST node addresses
* to symbol table entries */
PyObject *st_stack; /* list: stack of namespace info */
PyObject *st_global; /* borrowed ref to st_top->ste_symbols */
int st_nblocks; /* number of blocks used. kept for
consistency with the corresponding
compiler structure */
PyObject *st_private; /* name of current class or NULL */
PyFutureFeatures *st_future; /* module's future features that affect
the symbol table */
int recursion_depth; /* current recursion depth */
int recursion_limit; /* recursion limit */
};
要注意的重要字段是st_stack和st_blocks。st_stack字段是一个符号表项的堆栈。在构建符号表的第一遍过程中,CPython在进入相应的代码块时将一个条目推入堆栈,在退出相应的代码块时从堆栈中弹出一个条目。st_blocks字段是一个字典,编译器用它来获取一个给定AST节点的符号表条目。st_cur和st_top字段也很重要,但它们的含义应该是显而易见的。
要了解更多关于符号表及其构造的信息,我强烈推荐你Eli Bendersky的文章
基本块
符号表可以帮助我们翻译涉及变量的语句,如x = 1。但如果我们试图翻译一个更复杂的控制流语句,就会出现新的问题。考虑一下另一段隐晦的代码:
if x == 0 or x > 17:
y = True
else:
y = False
...
相应的AST子树有如下结构:
If(
test=BoolOp(...),
body=[...],
orelse=[...]
)
而编译器将其编译成以下字节码:
1 0 LOAD_NAME 0 (x)
2 LOAD_CONST 0 (0)
4 COMPARE_OP 2 (==)
6 POP_JUMP_IF_TRUE 16
8 LOAD_NAME 0 (x)
10 LOAD_CONST 1 (17)
12 COMPARE_OP 4 (>)
14 POP_JUMP_IF_FALSE 22
2 >> 16 LOAD_CONST 2 (True)
18 STORE_NAME 1 (y)
20 JUMP_FORWARD 4 (to 26)
4 >> 22 LOAD_CONST 3 (False)
24 STORE_NAME 1 (y)
5 >> 26 ...
该字节码是线性的。test节点的指令应该放在最前面,body块的指令应该放在orelse块的指令前面。控制流语句的问题是它们涉及到跳转,而跳转往往是在它所指向的指令之前发出的。在我们的例子中,如果第一次测试成功,我们想直接跳到第一条body 指令,但我们还不知道它应该在哪里。如果第二次测试失败,我们必须跳过body块到orelse块,但是第一条orelse指令的位置只有在我们编译了body块之后才会知道。
如果我们把每个区块的指令移到一个单独的数据结构中,就可以解决这个问题。然后,我们不再把跳转目标指定为字节码中的具体位置,而是指向这些数据结构。最后,当所有的块都被编译出来并且知道它们的大小时,我们就可以计算跳转的参数并将这些块组装成一个单一的指令序列。这就是编译器所做的。
我们正在谈论的块被称为基本块。它们不是CPython所特有的,尽管CPython的基本块概念与传统的定义不同。根据龙书的定义,一个基本块是一个最大的指令序列,应该如下:
1.控制只能进入该块的第一条指令;以及 2.控制在离开该块时没有停止或分支,可能在最后一条指令时除外。
CPython放弃了第二个。换句话说,除了第一条指令,基本块中的任何指令都不能成为跳转的目标,但基本块本身可以包含跳转指令。为了编译我们例子中的AST,编译器创建了四个基本块:
- 指令 0-14 对应
test - 指令 16-20 对应
body - 指令 22-24 对应
orelse; 最后 - 指令 26-… 为if语句之后的任何内容
一个基本块由 basicblock_结构表示,其定义如下:
typedef struct basicblock_ {
/* Each basicblock in a compilation unit is linked via b_list in the
reverse order that the block are allocated. b_list points to the next
block, not to be confused with b_next, which is next by control flow. */
struct basicblock_ *b_list;
/* number of instructions used */
int b_iused;
/* length of instruction array (b_instr) */
int b_ialloc;
/* pointer to an array of instructions, initially NULL */
struct instr *b_instr;
/* If b_next is non-NULL, it is a pointer to the next
block reached by normal control flow. */
struct basicblock_ *b_next;
/* b_seen is used to perform a DFS of basicblocks. */
unsigned b_seen : 1;
/* b_return is true if a RETURN_VALUE opcode is inserted. */
unsigned b_return : 1;
/* depth of stack upon entry of block, computed by stackdepth() */
int b_startdepth;
/* instruction offset for block, computed by assemble_jump_offsets() */
int b_offset;
} basicblock;
下面是 instr 结构的定义:
struct instr {
unsigned i_jabs : 1;
unsigned i_jrel : 1;
unsigned char i_opcode;
int i_oparg;
struct basicblock_ *i_target; /* target block (if jump instruction) */
int i_lineno;
};
我们可以看到,基本块不仅通过跳转指令连接,而且还通过b_list和b_next字段连接。编译器使用b_list来访问所有分配的块,例如,释放内存。b_next字段是我们现在更感兴趣的。正如注释所说,它指向正常控制流到达的下一个块,这意味着它可以被用来以正确的顺序组装块。再次回到我们的例子,test块指向body块,body块指向orelse块,orelse块指向if语句之后的块。由于基本块相互指向,它们形成一个图,称为控制流图(CFG)
frame blocks
还有一个问题需要解决:在编译 “continue “和 “break “等语句时,如何理解跳转到哪里?编译器通过引入另一种类型的块,即frame块来解决这个问题。有不同种类的frame块。例如,WHILE_LOOP frame块指向两个基本块:body块和while语句后的块。这些基本块分别在编译continue和break语句时使用。由于frame块可以嵌套,编译器使用堆栈对其进行跟踪,每个代码块有一个frame块堆栈。在处理try-except-finally等语句时,frame块也很有用,但我们现在不会纠缠于此。让我们来看看 fblockinfo 结构的定义。
enum fblocktype { WHILE_LOOP, FOR_LOOP, EXCEPT, FINALLY_TRY, FINALLY_END,
WITH, ASYNC_WITH, HANDLER_CLEANUP, POP_VALUE };
struct fblockinfo {
enum fblocktype fb_type;
basicblock *fb_block;
/* (optional) type-specific exit or cleanup block */
basicblock *fb_exit;
/* (optional) additional information required for unwinding */
void *fb_datum;
};
我们已经揭示了三个重要的问题,我们也看到了编译器是如何解决这些问题的。现在,让我们把所有东西放在一起,看看编译器是如何从头到尾工作的。
编译单元、编译器和汇编器
正如我们已经发现的,在建立符号表之后,编译器还要执行两个步骤,将AST转换为代码对象:
- 它创建了一个基本块的CFG;以及
- 它将一个CFG汇编成一个代码对象
这个两步过程是针对程序中的每个代码块进行的。编译器从建立模块的CFG开始,最后将模块的CFG汇编成模块的代码对象。在这之间,它通过递归调用compiler_visit_*和compiler_*函数来遍历AST,其中*表示被访问或编译的内容。例如,compiler_visit_stmt将给定语句的编译委托给适当的compiler_*函数,而compiler_if函数知道如何编译IfAST节点。如果一个节点引入了新的基本块,编译器会创建它们。如果一个节点开始了一个代码块,编译器会创建一个新的编译单元并进入该单元。编译单元是一个数据结构,它捕获了代码块的编译状态。它作为代码对象的一个可变的原型,并指向一个新的CFG。编译器在退出开始当前代码块的节点时,会汇编这个CFG。汇编后的代码对象被保存在父编译单元中。像往常一样,我鼓励你看一下结构定义:
struct compiler_unit {
PySTEntryObject *u_ste;
PyObject *u_name;
PyObject *u_qualname; /* dot-separated qualified name (lazy) */
int u_scope_type;
/* The following fields are dicts that map objects to
the index of them in co_XXX. The index is used as
the argument for opcodes that refer to those collections.
*/
PyObject *u_consts; /* all constants */
PyObject *u_names; /* all names */
PyObject *u_varnames; /* local variables */
PyObject *u_cellvars; /* cell variables */
PyObject *u_freevars; /* free variables */
PyObject *u_private; /* for private name mangling */
Py_ssize_t u_argcount; /* number of arguments for block */
Py_ssize_t u_posonlyargcount; /* number of positional only arguments for block */
Py_ssize_t u_kwonlyargcount; /* number of keyword only arguments for block */
/* Pointer to the most recently allocated block. By following b_list
members, you can reach all early allocated blocks. */
basicblock *u_blocks;
basicblock *u_curblock; /* pointer to current block */
int u_nfblocks;
struct fblockinfo u_fblock[CO_MAXBLOCKS];
int u_firstlineno; /* the first lineno of the block */
int u_lineno; /* the lineno for the current stmt */
int u_col_offset; /* the offset of the current stmt */
};
另一个对编译至关重要的数据结构是 compiler结构,它表示编译的全局状态。下面是它的定义:
struct compiler {
PyObject *c_filename;
struct symtable *c_st;
PyFutureFeatures *c_future; /* pointer to module's __future__ */
PyCompilerFlags *c_flags;
int c_optimize; /* optimization level */
int c_interactive; /* true if in interactive mode */
int c_nestlevel;
int c_do_not_emit_bytecode; /* The compiler won't emit any bytecode
if this value is different from zero.
This can be used to temporarily visit
nodes without emitting bytecode to
check only errors. */
PyObject *c_const_cache; /* Python dict holding all constants,
including names tuple */
struct compiler_unit *u; /* compiler state for current block */
PyObject *c_stack; /* Python list holding compiler_unit ptrs */
PyArena *c_arena; /* pointer to memory allocation arena */
};
而定义前面的注释解释了两个最重要的字段是什么,是为了什么:
u指针指向当前的编译单元,而enclosing的单元则存储在c_stack中。u和c_stack由compiler_enter_scope()和compiler_exit_scope()管理。
为了将基本块组装成一个代码对象,编译器首先要通过将指针替换成字节码 中的位置来修复跳转指令。一方面,这是一个简单的任务,因为所有的基本块的大小 是已知的。另外一方面,当我们修复一个跳转的时候,基本块的大小可能会发生变化。目前 的解决方案是,在大小发生变化的时候,在一个循环中不断修复跳转。下面是源代码中对这个 解决方案的一个注释:
这是一个可怕的hack,可能会损失性能,但是从好的方面看,在我们想出更好的解决方案前,他是可以工作的。
剩下的就很简单了。编译器对基本块进行迭代并发出指令。进展被保存在 assembler 的结构中:
struct assembler {
PyObject *a_bytecode; /* string containing bytecode */
int a_offset; /* offset into bytecode */
int a_nblocks; /* number of reachable blocks */
basicblock **a_postorder; /* list of blocks in dfs postorder */
PyObject *a_lnotab; /* string containing lnotab */
int a_lnotab_off; /* offset into lnotab */
int a_lineno; /* last lineno of emitted instruction */
int a_lineno_off; /* bytecode offset of last lineno */
};
在这一点上,当前的编译单元和汇编器包含了创建一个代码对象所需的所有数据。祝贺你! 我们几乎完成了!
peephole optimizer
创建代码对象的最后一步是优化字节码。这是peephole optimizer的工作。 下面是它所执行的一些优化类型:
- 像语句
if True: ...和while True: ...生成一个由LOAD_CONST trueconst和POP_JUMP_IF_FALSE指令组成的序列。 peephole optimizer 消除了这种指令。 - 像语句
a, = b,会构建元组的字节码,然后解包它。peephole optimizer用一个简单的赋值来取代它。 - peephole optimizer会删除
RETURN之后永远不会执行的指令。
本质上,peephole optimizer删除了多余的指令,从而使字节码更加紧凑。在字节码被优化后,编译器创建了代码对象,而虚拟机则准备执行它。
Summary
这是一篇很长的文章,所以总结一下我们所学到的东西也许是个好主意。CPython编译器的架构遵循传统设计。它的两个主要部分是前端和后端。前端也被称为解析器。它的工作是将源代码转换为AST。解析器从标记器中获得标记,标记器负责从文本中产生有意义的语言单元流。历史上,解析由几个步骤组成,包括生成解析树和将解析树转换为AST。在CPython 3.9中,新的解析器被引入。它基于一个解析表达式的语法,并直接产生一个AST。后端,自相矛盾地称为编译器,接受AST并产生一个代码对象。它通过首先建立一个符号表,然后创建一个称为控制流图的程序的中间表示法来做到这一点。CFG被组装成一个单一的指令序列,然后由peephole optimizer进行优化。最终,代码对象被创建。
在这一点上,我们有足够的知识来熟悉CPython源代码,并了解它的一些工作。这是我们为下一篇制定的计划.